

Deduping candidates is a recruitment database isn’t always as easy as it sounds, especially if number of candidates reaches a certain volume.

“Deduping candidates requires a more delicate and sophisticated matching process than when deduping business contacts”
Surprise: It’s more than just matching emails
A traditional deduplication approach using a matching on first name, last name and email doesn’t necessarily give the same results for a candidate database as it would do for a database with business accounts.
Here’s a few examples:
| Business Contacts | Candidate Contacts |
| Email is a good key, as businesses usually only issue one (1) email per employee, but some has none and some provide generic emails like info@ | May provide you with one of many private email addresses. |
| Mobile, office phone, switchboard number: you never really know what the phone field contain as primary phone.
Prospects may even provide you with a switchboard number to avoid too many direct calls. |
Normally private phones and mobile phones are kept apart. A candidate is most likely making sure that the number provided, is a number where he/she can be reached, so this is reliable data. But a cross check between multiple phone numbers are still required as the numbers could be stored in separate fields. |
| The address provide is often the office address, which is useful when e.g. there are more companies on the same location, and the company names are spelled slightly different. Two contacts with similar names on the same location is more likely a duplicate than if they are in different geographical regions. | The address is most likely the private address. But as people change jobs they may also relocate and thus change their address. 2 duplicate candidates could therefor easily have completely different addresses. |
“Building match rules e.g. based on same name + same email, or same name + same address will NOT give you the full picture in a candidate database.”
Taking an broader approach to identifying duplicate candidates
Matching candidates require a more delicate or sophisticated matching process. A process where multiple elements; name, emails, phones, addresses etc. are all included in the comparison. And where the correlating information elements for the 2 records adds to the likeliness of them being the same person.
The likeliness or Confidence Indicator will help you effectively resolve these potential duplicates in a stuctured and prioritized order.
You might safely merge the obvious (exact) matches and get rid of the most obvious duplicates in your database in a few clicks, but for the records with a lower confidence classification you may need to review and be more careful.
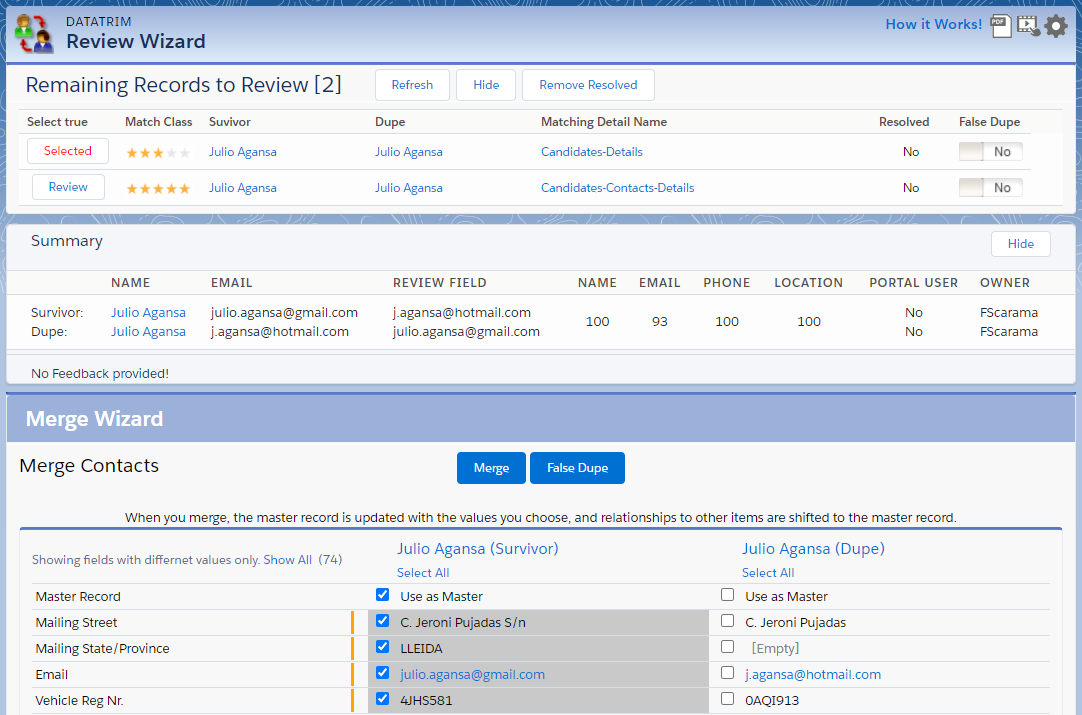
Choosing the Survivor
When you merge 2 candidates, the data from the dupe is consolidated towards the survivor, but the existing data on the Survivor takes priority.
It is important to be able to choose which candidate should be considered survivor and under which circumstances.
We call this survivorship rules.
A new candidate, e.g. from a website posting, will most likely contain more up-to-date contact details than the existing candidate record. The new records should therefore logically be your survivor.
But if the existing candidate already have job placements, you may have information on the existing record which you prefer to keep over the new data.
So, don’t’ treat all duplicates the same way!
Read more: Merging Records – Survivorship considerations
Merging is not a one-button thing!
When deduping candidates it is important that you think about segmenting your data. By matching subsegments of candidates separately, you can merge the duplicates from each subsegment in the same way.
Example: When matching candidates consider these 3 segments:
- Match candidates without placements
- Candidates with placements
- Match candidates with placements against candidates without placement.
You can now treat the potential duplicates from each of the 3 segments differently and make sure they are merged correctly.
As an alternative to segmenting the data during matching, you can segment the outcome, -the potential duplicates.
By applying logic, for each of the matched pairs, you can get an indication/recommendation for how each pair of potential duplicates should be merged.
We call this Advanced Survivorship rules.
To better understand which approach works best for you note that deduplication is a 2-step process:
- Matching the selected records and identification of potential duplicates
- Reviewing the potential duplicates and taking appropriate actions.
Deduping candidates should be a multi-step process.
By segmenting your data in the matching process, you make the reviewing simpler.
-Or you can segment the outcome – the potential duplicates, –and by means of your survivorship rules decide how to merge the dupes.
The segmentation of data also allows you to prioritize the matching and merging process. Making sure that you clean up the most important data first.
Mixing Candidates with Contacts
Another obvious reason to segment your data, is the ability to keep candidates and business contacts apart.
In most ATS apps, based on the salesforce ™ platform, Candidates and Business Contacts are all stored in the same database table: Contacts.
If you don’t segment your data, but simply match data from your Contact table (Object), you will get Candidates and Contacts mixed up in the same matching process.
-an when you then review, you will have to deal with Candidate-Candidate, Contact-Contact, and Candidate-Contact duplicates.
You might even consider having different users merging candidates and business contacts.
And for the Candidate-Contact duplicates? Do you really want to merge these different record types?
If your situations where a candidate record also is a business contact, you may not necessarily want to merge the records. Why not link them together?
This way, regardless of whether you are the account manager working the business contacts or the recruiter working the candidate, -you will still get the full picture.
Involving the end-user – the recruiter – when deduping candidates
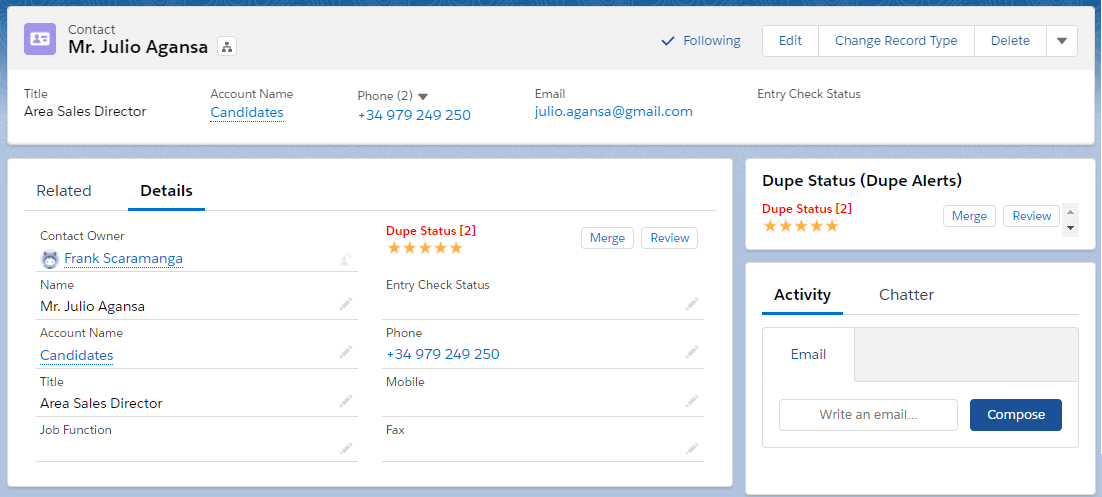
The earlier you can detect that the new candidate is a potential duplicate of an existing candidate, the more time are you saving in qualifying and understanding the history of the candidate.
Make sure you have some sort of Dupe Detection upon Entry enabled.
A feature which guides the user in the candidate creation process, and checks if the candidate already exists. Or being able to see if a candidate, freshy, assigned to them is a potential duplicate candidate or not.
For the reviewing and merging of the potential duplicates you should consider leaving all or partly to the recruiter.
By making the information about the duplicates available to the recruiters, they can then merge the duplicates, and make sure, that your data is complete, valid and up-to-date.
Summary
Keeping data clean in an Applicant Tracking Solution (ATS) is not a trivial job.
Many may think of data as a consumable, but data is a very valuable asset.
A plan, apps and methods should exist to make sure that this asset doesn’t deteriorate over time.
Bad quality data will undermine the effectiveness of your ATS solution.
- Go beyond simple matching.
- Use segmentation techniques (sub-sets of data) to speed up the end-to-end processing times. This applies to matching, reviewing and the merging of your candidate and contact records.
- Consider engaging end-users. It’s not always the Admin who has the best insight into which data elements are the most valuable, -often the recruiter knows better.
Additional Reads:
Managing the Candidate Database in Your Applicant Tracking System from TargetRecruit.
-or Dive deeper: 5 Tips to consider when deduping Candidates in an Applicant Tracking Solution (ATS) from DataTrim.
DataTrim is a certified salesforce ISV partner who provides deduplication solutions for salesforce, regardless of how your data enter salesforce, we have a solution for you, read more at: www.datatrim.com