
In a constant effort to improve the matching algorithms and make them better and better we continuously introduce new Advanced Parameters, for you to optimize the matching process.
Our comparison routines are highly complex algorithms, which are capable of analysing the content of the fields and find the words which are the most significant and thus which words to weight heaviest during the scoring process.
Here are a few examples of how our algorithms are capable of improving the matching by ‘understanding’ and process the field values.
Example A: If you have 2 account names: ‘ABC Incorporated’ and ‘XYZ Incorporated’, our algorithm will recognize the word “incorporated” and flag this as a company legal type which is more of a descriptive nature than actually the company name, so the comparison and the score will mainly be derived from comparing ‘ABC’ against ‘XYZ’, i.e. the score is more qualitatively more accurate than if the whole field values where compared.
Example B: Account A: ‘International Business Machines’ and Account B: ‘IBM’
Based on a list of Normalization formulas our solution will recognize ‘International Business Machines’ (A) and NORMALIZE this into ‘IBM’ during the comparison, so that the final comparison is between ‘IBM’ (A) and ‘IBM’ (B)
Example C: Account A: ‘St Mary’s Hospital’, Account B: ‘SaintMarysHospital’
In this example our solution will again NORMALIZE the word ‘Saint’ into ‘St’, and identify the word ‘Hospital’ as a description word, thus the main comparison will be by comparing ‘St Mary’s’ (A) with ‘Saint Marys’ (B)
Example D: Email A: ‘Unknown@Unknown.com, Email B: ‘info@datatrim.com’
In this example our solution will reference the list and identify the Email of A as a dummy email (used as a place holder). The advantage of this is that the comparison is now between a value (B) and a blank field.The score in this case is 0, and can therefore easily be identified in the review process by filters etc, on the Email score field. Whereas a normal comparison on the 2 original emails is likely to give a score of somewhere between 1 and 75, and can in many cases be perceived as a comparison between 2 valid emails.
In the 4 examples above our matching algorithm is supported by an internal reference database containing 1000’s of words to be RELAX’ed about, to NORMALIZE or to IGNORE
Although our list is long and we constantly are adding to it on your behalf, it might be that your database contains words which to your data become significant for the deduplication process.
In a database where you have account names from all over the world, the word “Florida” may not be frequent in account names, but if you are a local company in Florida and you happen to work with the public sector you are likely to have the word ‘Florida’ in many of your account names.
To address this and related specific needs we have Advanced parameters which allows you to add custom word to the list, so that our algorithm will use the standard set plus anything you want to add.
The 3 parameters are defined as follows:
Relax:=
Normalize:=
Exclude:=
Where
Where < NormalizedWord> is the normalized word to be used for the comparison.
Where
ORGNAME
EMAIL
ALL
Examples (Relax):
Relax:=ORGNAME:Builders
Relax:=ORGNAME:Telco
Relax:=ORGNAME:Sparkasse
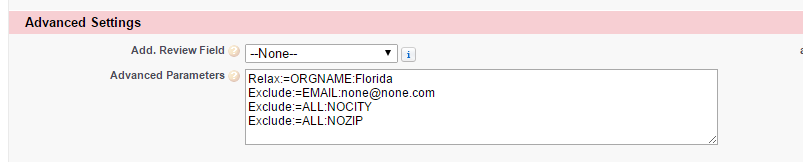
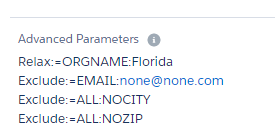
Relax:=ORGNAME:Florida
Relax:=ORGNAME:Tampa
Relax:=ORGNAME:Miami
Examples (Normalize):
Normalize:=ORGNAME:sforce=salesforce
Normalize:=ORGNAME:BMS=Bristol-Myers Squibb
Normalize:=ORGNAME:Minnesota Mining and Manufacturing Company=3M
Normalize:=NAME:Dave=David
Examples (Exclude):
Exclude:=EMAIL:.@.com
Exclude:=EMAIL:none@none.com
Exclude:=EMAIL:noreply@none.com
Exclude:=ALL:NOCITY
Exclude:=ALL:NOZIP
Exclude:=ALL:LastName
Exclude:=ALL:FirstName
Classic View, of field on the DataTrim Dupe Alert:
Lightning View:
Note you can of cause have multiple words for each Advanced Parameter (in comparison to other advanced parameters which are single line parameters).
TIPS: You might eventually hit the limit of the size of the Advanced Parameters text field in salesforce. You can increase the size but you can also replace the key words: ‘Relax’ with ‘R’, ‘Normalize’ with ‘N’ and ‘Exclude’ with ‘E’ to save space.
This functionality is available to all users DataTrim Dupe Alerts